As artificial intelligence continues to revolutionize how we process and generate information, two innovative methods have emerged to enhance AI’s generative capabilities—Retrieval Augmented Generation (RAG) and Table Augmented Generation (TAG). Both techniques improve the quality, accuracy, and context of AI-generated content by leveraging external data sources. However, they do so in fundamentally different ways.
RAG enriches responses by retrieving relevant unstructured information from large datasets, while TAG focuses on generating text that directly reflects structured data from tables or databases. Understanding the distinctions between these methods is essential for choosing the right approach based on your use case, whether it’s content creation, data reporting, or answering complex queries.
In our previous blog on RAG, we went into the details of RAG, from its implementation to benefits, and everything. But here in this blog, we’ll dive deep into the comparison of the RAG process and TAG, explore how they work, and compare their strengths and limitations to help you decide which one best suits your AI-driven needs.
What is RAG (Retrieval-Augmented Generation)?
Retrieval augmented generation (RAG) is an advanced approach that combines the strengths of retrieval augmented language models and generative models to improve the accuracy and relevance of generated text.
The core idea behind RAG is to augment the generative model (typically based on transformers like GPT) with a retrieval system. This retrieval system pulls relevant information from external sources, such as a large corpus of documents, to guide and enrich the generated responses. The generative model can then use this information to create more accurate, fact-based content.
How RAG Works:
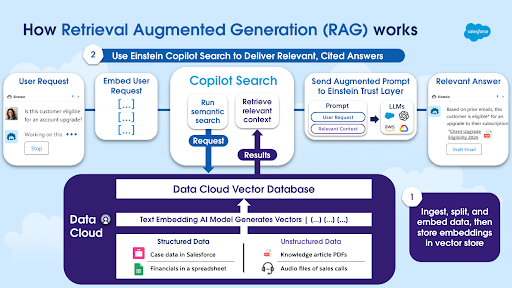
Rag AI Architecture
1. Retrieval Step:
The Retrieval Step is the first critical phase in the RAG process. When a user provides a query or prompt, the system doesn’t rely solely on the internal knowledge of the AI model to generate a response. Instead, it actively seeks out additional, relevant information from external data sources like large document collections, databases, or knowledge bases. This ensures that the AI model has access to the most accurate, up-to-date, and relevant information when crafting its response.
2. Generation Step:
In the Generation Step of RAG (Retrieval Augmented Generation), the generative model uses the information retrieved from external sources to craft a response that is both contextually relevant and factually accurate. Instead of simply copying the retrieved content, the model synthesizes this data with the original query to generate coherent and natural text. By integrating real-time, external information, this step improves the quality and reliability of the output, ensuring that the response is not only aligned with the user’s query but also enriched with up-to-date facts. This results in more accurate, detailed, and informative AI-generated content.
Key Components of RAG:
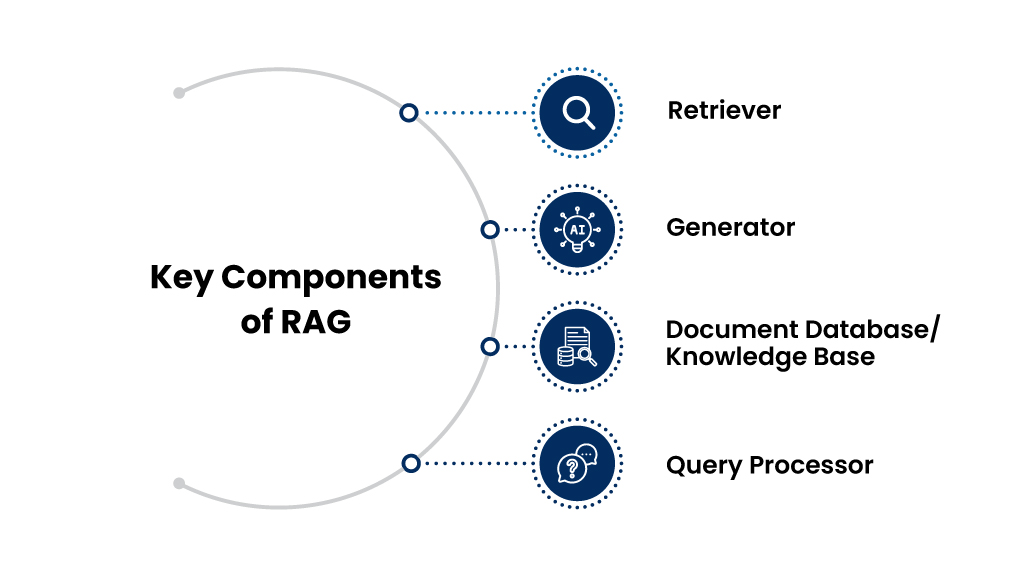
1. Retriever:
This component is responsible for fetching relevant pieces of information from a large external dataset, knowledge base, or document collection. It uses search algorithms (such as BM25 or dense retrievers) to rank and retrieve the most relevant data based on the input query.
2. Generator:
The generative model (usually a transformer-based model like GPT) takes the retrieved information and the original query to produce coherent, contextually accurate, and factually correct text. It synthesizes the retrieved data to generate a response that integrates the relevant facts and details.
3. Document Database/Knowledge Base:
The external corpus or dataset from which the retriever pulls relevant information. This can be a large collection of documents, articles, research papers, or any other form of unstructured data that the retriever uses to find answers.
4. Query Processor:
This component interprets the input query or prompt, allowing the retriever to search for the most relevant content and helping the generator understand the context in which the response should be framed.
These components work together to create a more informed and accurate response by combining the strengths of both retrieval-based and generative models.
Applications of RAG (in the context of AI Copilots)
Here are the top 3 applications of Retrieval Augmented Generation (RAG) specifically in the context of AI Copilot:
1. Sales Support and Recommendations:
AI Copilot can leverage RAG to pull real-time information from CRM systems, customer profiles, and market data to generate personalized sales pitches, product recommendations, or outreach emails. For example, it can retrieve recent customer interactions or relevant product details to craft a custom email for a potential lead.
2. Customer Service Automation:
With RAG, AI Copilot can retrieve information from support tickets, knowledge bases, or customer databases to provide accurate and timely responses to customer inquiries. For instance, if a customer asks about a product issue, AI Copilot can retrieve past solutions, troubleshooting steps, or FAQs and generate a personalized response, improving both efficiency and customer satisfaction.
3. Real-Time Business Insights:
AI Copilot can use RAG to gather and summarize real-time business data for reports, dashboards, or performance reviews. By retrieving relevant sales, revenue, or performance metrics from various data sources, AI Copilot can generate comprehensive insights or recommendations that help business leaders make data-driven decisions.
What is TAG (Table Augmented Generation)?
Table Augmented Generation (TAG), on the other hand, is a specialized form of text generation that uses structured data from tables to inform the output of the generative model. Instead of relying on free-text retrieval, TAG systems extract data from tabular datasets—like spreadsheets, databases, or knowledge graphs—and incorporate that data into the generated output.
TAG is particularly useful in scenarios where the output needs to be based on numerical, categorical, or structured information that can be found in tables. The generated content is therefore rooted in the exact values and relationships present in the table, making it a powerful tool for creating content that requires precision and consistency.
How TAG Works
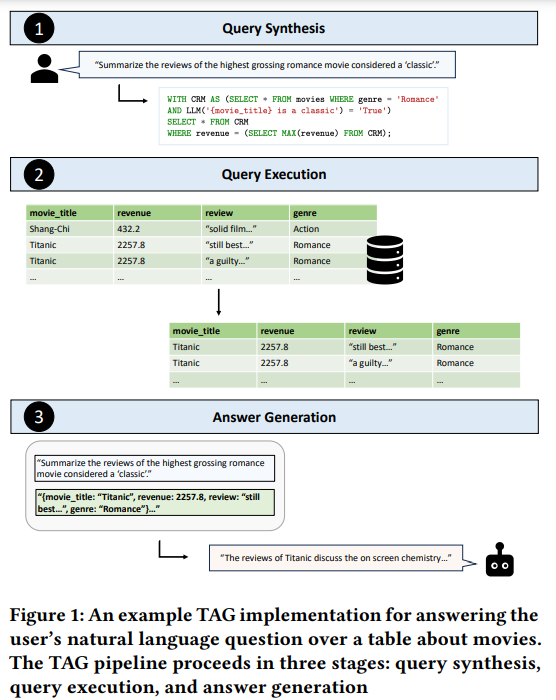
1. Table Extraction:
In this step, when a user provides a query or prompt (for example, “Generate a report on sales performance for Q1”), the system identifies relevant structured data sources, such as tables from databases or spreadsheets. The system analyzes the content of these tables to find specific rows, columns, or entries that are relevant to the user’s request. This could include sales figures, customer data, or product information from a financial or business report table.
2. Data Fusion:
Once the relevant table or data from structured sources is extracted, the next step is to combine this data with a generative model, such as GPT. Here, the model takes the raw data from the table (numbers, facts, and relationships between different fields) and integrates it into the generative process. The model doesn’t just list the numbers but uses them to generate coherent text that explains or interprets the table’s data, such as “Sales increased by 15% in Q1 compared to Q4, driven by a rise in product X sales.”
3. Generation Step:
The final step is where the generative model produces fluent and coherent text based on the structured data. The output could be a summary, a report, or any content that reflects the relationships and values present in the table. The model ensures that the generated content aligns accurately with the original structured data, maintaining consistency in terms of the numbers and insights derived from the table. This guarantees that the final text not only makes sense but is also grounded in the actual data from the extracted tables.
In this process, the AI can generate highly accurate and fact-based content, making it ideal for applications like financial reporting, product summaries, or automated business analysis where precise numerical and structured data need to be incorporated into natural language text.
Key Components of TAG
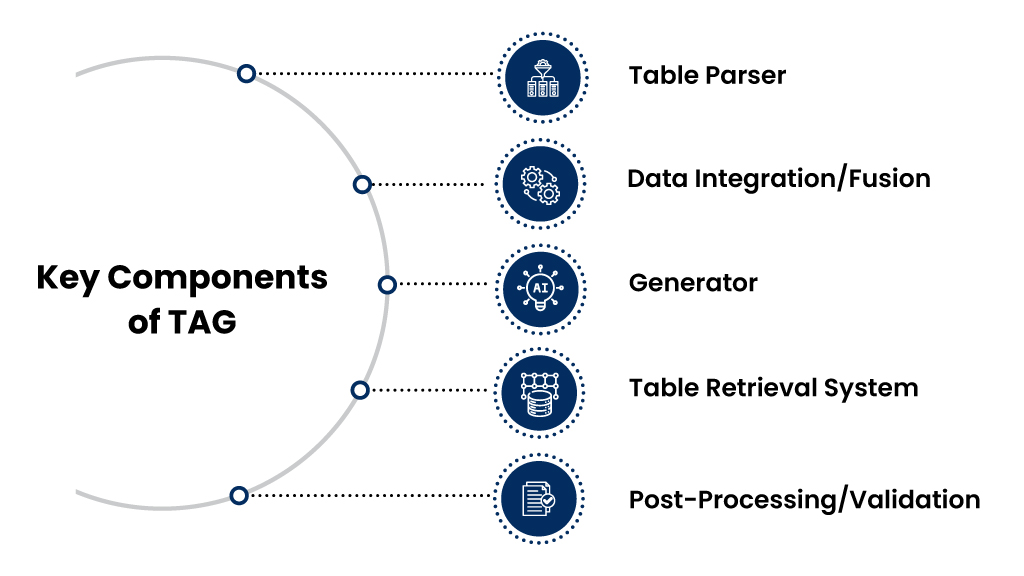
The key components of Table Augmented Generation (TAG) are:
1. Table Parser:
This component is responsible for identifying and extracting relevant structured data from tables, spreadsheets, or databases based on the user’s query or prompt. It analyzes the table’s structure (rows, columns, headers) to extract useful information that aligns with the input request.
2. Data Integration/Fusion:
After extracting the relevant table data, this component integrates the structured data with the generative model. The data is embedded into the model’s generation process, allowing the AI to incorporate facts, figures, and relationships from the table into the generated text.
3. Generator:
This is the core generative model (e.g., GPT, BERT) that produces human-readable text. The generator synthesizes the extracted table data and creates output that reflects the structure and information from the table, ensuring the generated text is coherent, contextually relevant, and factually accurate.
4. Table Retrieval System:
In cases where there are multiple tables or data sources, this system retrieves the most relevant tables or structured data to the prompt. It decides which tables or portions of structured data will be used to generate the desired content.
5. Post-Processing/Validation:
This component ensures that the generated text aligns correctly with the structured data and that the factual accuracy of the output matches the original data. It may involve verifying numbers, dates, and relationships from the table to prevent errors in the final content.
These components work together in TAG to ensure that structured data from tables is accurately and seamlessly incorporated into the text generation process, making it ideal for applications like report writing, data summarization, or any content where precision is crucial.
Applications of TAG
Table augmented generation has the power to transform structured data into readable, insightful content, automating tasks like reporting and analysis while ensuring precision and factual accuracy.
1. Financial Report Generation
TAG is highly effective in generating financial reports from structured data such as balance sheets, income statements, and sales data. For example, a system can extract key financial metrics (e.g., revenue, profit margins, expenses) from a spreadsheet and then generate a detailed financial summary. The generated report can describe how revenue has grown over the past quarter, highlight changes in operating costs, and forecast future financial trends. TAG ensures that the generated content is accurate and consistent with the underlying data, making it ideal for automated financial analysis and reporting.
2. Product or Market Analysis
In industries like e-commerce or retail, TAG can be used to automatically generate product descriptions, sales summaries, or market trend reports. For example, it can extract structured data on product sales, customer reviews, or pricing trends and then generate summaries or insights. A TAG model could generate content like, “Product A saw a 25% increase in sales during Q3, driven by high demand in North America,” providing data-driven insights while ensuring the information is grounded in the extracted table data.
3. Sports Reporting and Statistics Summarization
TAG is also well-suited for automatically generating sports reports and summarizing statistics from game results, player performance data, or league standings. For example, after a football match, a TAG model can extract structured data such as goals, assists, and possession percentages from match statistics tables and then produce a coherent match summary. The generated content might read, “Team A dominated possession with 65%, securing a 2-1 victory thanks to Player X’s late goal,” seamlessly blending numerical data with natural language generation.
Benefits of RAG
Enriched Responses:
RAG improves the quality of generated text by leveraging external, often larger and more diverse, knowledge bases.
Real-Time Information:
The retrieval data component ensures that the generated content remains relevant by fetching up-to-date information.
Scalability:
RAG systems can be applied across a wide range of topics and domains, especially in areas like customer support and knowledge-based systems.
Benefits of TAG
1. Accuracy:
TAG provides highly accurate and reliable outputs when dealing with structured data like tables or databases, making it ideal for data-centric tasks.
2. Data-to-Text Conversion.
TAG excels at transforming complex, structured datasets into readable, natural language summaries.
3. Business-Centric Applications:
TAG is especially useful in industries like finance, journalism, and e-commerce, where structured data plays a critical role.
Key Differences Between RAG and TAG
| Feature | RAG (Retrieval Augmented Generation) | TAG (Table Augmented Generation) |
|---|---|---|
| Data Source | Unstructured data (documents, articles, knowledge bases) | Structured data (tables, spreadsheets, databases) |
| Type of Input | Free-text queries or prompts | Structured data queries or prompts requiring table data |
| Output Style | Text enriched with facts and data retrieved from external documents | Text generated based on exact values and relationships found in structured data |
| Use Case Focus | Fact-based question-answering, content generation | Data-driven reports, summaries, business analysis |
| Reliability of Output | Depends on the accuracy of the retrieved documents | Highly reliable when based on structured data, which is often precise |
| Complexity of Data | Capable of handling large amounts of unstructured data | Limited to structured, relational, or numerical data |
| Applications | Content creation, customer support, knowledge retrieval, question-answering | Financial reports, sports summaries, structured data-to-text systems |
| Challenges | Retrieval inaccuracies, dependency on the quality of external sources | Limited to scenarios where structured data is available |
Choosing Between RAG and TAG
The choice between RAG and TAG depends on your specific requirements and the type of data you are working with:
Use RAG if:
You are working with unstructured data, such as documents, articles, or knowledge bases.
You need to generate responses enriched with external information that might not be available in a structured format.
You want to build systems for open-domain question-answering, customer support bots, or content generation.
Use TAG if:
You have access to structured data like tables, spreadsheets, or databases.
You need precise, data-driven outputs such as financial reports, business summaries, or automated news generation.
Your use case demands high accuracy in representing data, such as in business analytics or performance reporting.
Wrap-up
Both RAG and TAG represent powerful advancements in the field of NLP and AI, with each serving distinct needs. RAG is more flexible and powerful when dealing with large, unstructured datasets, making it ideal for content generation and open-domain tasks. TAG, on the other hand, is highly accurate and reliable when working with structured data, making it invaluable for tasks that demand precision and clarity in representing numerical or tabular data.
By understanding the differences between RAG and TAG, you can better determine which approach suits your needs, whether you’re building a chatbot, generating business reports, or creating a system for automated content generation. Both approaches offer exciting possibilities for enhancing the quality and relevance of AI-generated content.
Want to know more? Get in touch with our product experts today!