Data is the backbone of each and every organization today. And this data, lying in siloes is of no use. Hence, integrating all of this siloed data is extremely important to actually do something out of that data. And to integrate this data, various methodologies have emerged. A few of them are ETL, ELT, Reverse ETL and Zero ETL. These methodologies are like the four options that you used to get in the Multiple Choice Questions (in probably the third grade?).
Before any organization takes a decision of which one they must choose, it is crucial to understand what these methods are, how to use them and how they are different from each other- Difference between ETL and ELT is the most important out of all. They can’t be blindly filling out the circle of the OMR sheet like you used to do (in probably the third grade?).
In this blog, we will explore these data integration techniques, highlighting their unique characteristics and appropriate use cases.
ETL (Extract, Transform, Load)
What is ETL?
ETL stands for Extract, Transform, Load. This traditional method involves extracting data from various sources, massaging and transforming it into a suitable format requited by systems, and loading it into a data warehouse or database.
This is how it works-
Zero ETL is an emerging concept where data integration happens without the traditional ETL processes. Instead, data is directly queried and analyzed from its original source. This approach aims to minimize or eliminate the traditional ETL process by integrating data directly between systems in real-time or near real-time. It typically involves the use of data integration platforms or tools like 200 OK that allow seamless data flow and transformation on-the-fly without the need for intermediate staging or batch processing. Zero ETL focuses on reducing latency and complexity in data integration processes.
This is how it works-
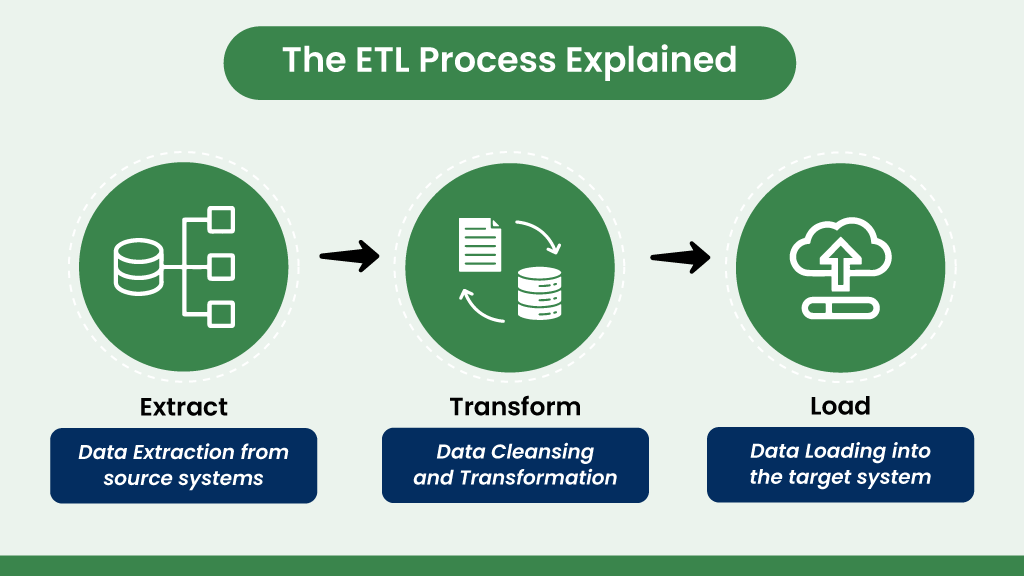
Extract: Data is collected from different sources such as databases, APIs, and flat files.
Transform: The extracted data is cleaned, aggregated, and transformed into a desired format or structure.
Load: The transformed data is loaded into a target system, mostly a data warehouse or database.
ETL, which is the traditional approach to data integration, ensures data quality before loading but can be time-consuming and resource-intensive.
Use Cases:
Data Warehousing: ETL is commonly used to populate data warehouses, ensuring that data is clean and well-structured.
Business Intelligence (BI): ETL processes support BI tools by providing high-quality, consistent data for reporting and analysis.
Regulatory Compliance: Organizations use ETL to ensure that data is transformed and stored in compliance with regulatory requirements.
ELT (Extract, Load, Transform)
What is ELT?
ELT stands for Extract, Load, Transform. Unlike ETL, ELT involves extracting data from sources, loading it directly into the target system, and then transforming it.
This is how it works-
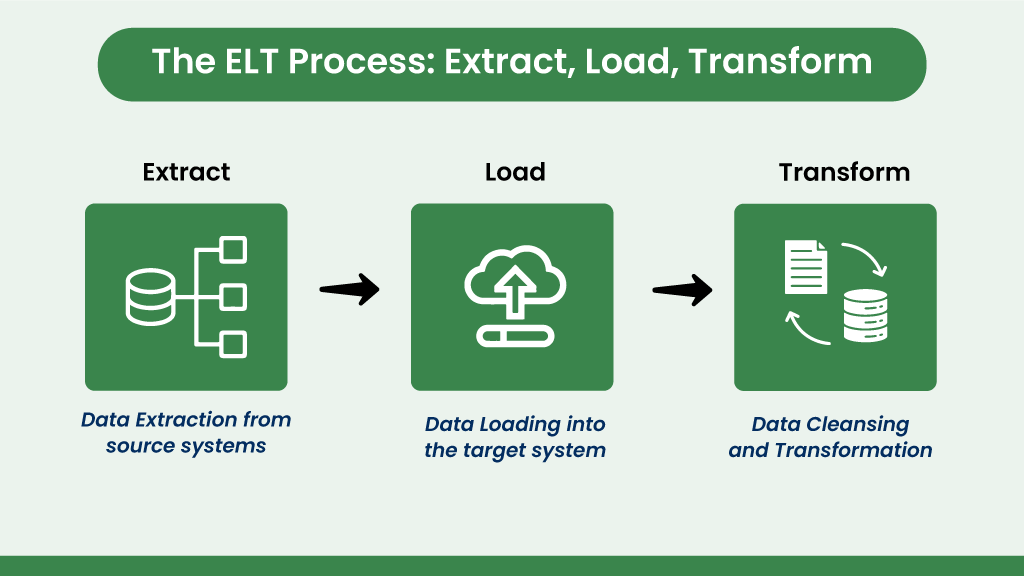
Extract: Similar to ETL, data is gathered from various sources.
Load: The raw- extracted data is loaded directly into the target system, usually a data lake or cloud-based data storage.
Transform: Transformation processes occur within the target system using its processing power.
Use Cases:
Big Data Environments: ELT is well-suited for big data platforms like Hadoop and cloud-based data warehouses (e.g., Snowflake, Google BigQuery) that can handle large volumes of data and perform complex transformations efficiently.
Real-Time Analytics: ELT supports real-time data processing, enabling organizations to analyze data as soon as it is loaded.
Scalability: ELT is ideal for scalable systems that can manage the computational load of transforming large datasets.
Reverse ETL
What is Reverse ETL?
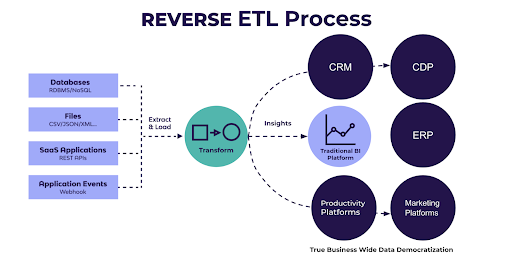
Extract: Data is extracted from the data warehouse or data lake.
Load: The extracted data is loaded into operational systems.
Transform: Transformation may occur before or after loading, depending on the operational system’s requirements.
Use Cases:
Operational Analytics: Reverse ETL enables organizations to use analytical data in operational systems to enhance decision-making and improve business processes.
Personalization: Companies can leverage customer data from data warehouses to personalize marketing campaigns and customer interactions.
Data Synchronization: Reverse ETL helps keep operational systems in sync with the latest data from the central repository.
Zero ETL
What is Zero ETL?
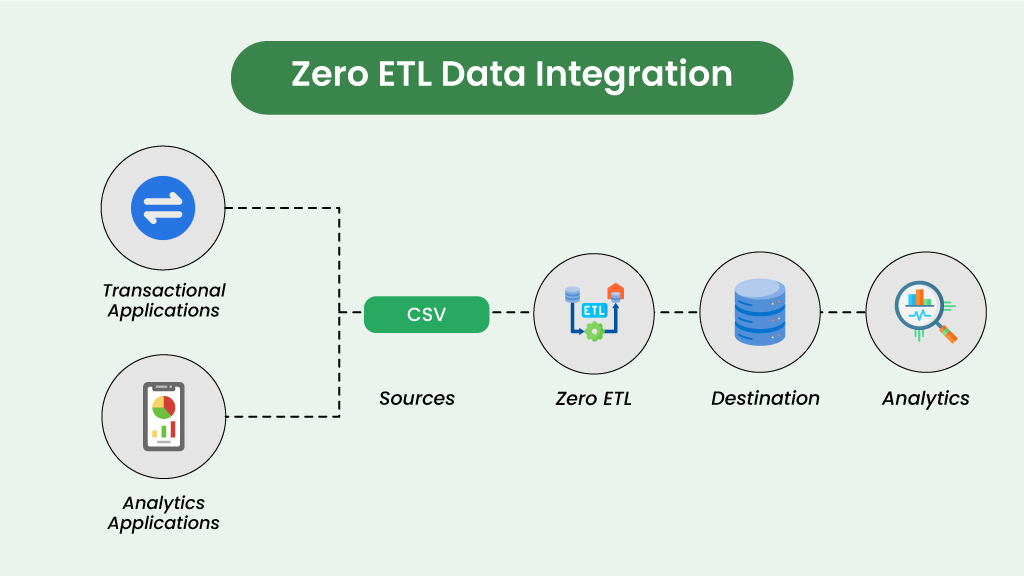
Zero ETL is an emerging concept where data integration happens without the traditional ETL processes. Instead, data is directly queried and analyzed from its original source. This approach aims to minimize or eliminate the traditional ETL process by integrating data directly between systems in real-time or near real-time. It typically involves the use of data integration platforms or tools like 200 OK that allow seamless data flow and transformation on-the-fly without the need for intermediate staging or batch processing. Zero ETL focuses on reducing latency and complexity in data integration processes.
This is how it works-
Direct Query: Data is queried directly from the source without extraction or transformation.
Real-Time Access: Real-time access to data is provided without the need for loading into a separate system.
Use Cases:
Real-Time Reporting: Zero ETL is ideal for real-time reporting and analytics, providing immediate insights from live data.
Minimal Data Movement: Organizations looking to minimize data movement and duplication benefit from Zero ETL.
Cost Efficiency: Zero ETL reduces the need for extensive data infrastructure, lowering costs associated with data storage and processing.
Comparative Analysis- Reverse ETL vs ETL vs ELT
| Feature | ETL | ELT | Reverse ETL | Zero ETL |
|---|---|---|---|---|
| Latency | Typically involves batch processing, leading to higher latency. | Can leverage real-time transformation capabilities of target systems but often involves batch loading. | Reverse ETL:* Usually operates in real-time or near real-time to update operational systems. | Focuses on real-time or near real-time data integration, minimizing latency. |
| Data Transformation | Before loading | After loading | Varies | No traditional transformation |
| Data Movement | Multiple steps | Direct loading | From data warehouse to ops systems | Minimal movement |
| Transformation Location | Before loading data into the target system | After loading data into the target system. | After extracting data from the data warehouse. | During the data transfer process |
| Scalability | Moderate | High | Depends on target systems | High |
| Real-Time Processing | Limited | Strong | Strong | Strong |
| Infrastructure Requirement | Extensive | Requires powerful target systems | Requires integration with ops systems | Minimal |
Wrap-Up
Understanding the difference between ETL, ELT, Reverse ETL, and Zero ETL is essential for choosing the right data integration strategy for your organization. ETL remains a reliable choice for traditional data warehousing and compliance, while ELT is better suited for modern, scalable environments requiring real-time analytics. Reverse ETL bridges the gap between data warehouses and operational systems, enhancing business processes with analytical insights. Zero ETL represents the future of data integration, offering real-time access and minimal data movement.
By selecting the appropriate approach based on your specific needs and infrastructure, you can ensure efficient and effective data integration, driving better business outcomes.
Want a reliable partner who can provide you your choice of integration strategy? We’re here for you! Get in touch with our product experts today.